Le Web 2.0 ne naÓt pas de rien. Il est le produit d'une histoire, certes brŤve (une quarantaine d'annťes), mais intense. Elle est faite du mutations sociales et culturelles, mais aussi de protocoles. C'est une histoire de protocoles et de formats. Racontons-lŗ.
Au commencement n'ťtait pas le web, mais Internet.
C'est en 1969 que de Dťpartement de la Dťfense des …tats-Unis mit en úuvre le rťseau Arpanet qui permettait ŗ des ordinateurs distants d'Ítre tous reliťs entre eux de telle faÁon qu'une attaque sur une partie du rťseau ne l'empÍche pas de fonctionner.
Ce rťseau fut ensuite utilisť par les universitťs amťricaines, les grandes administrations, les musťes et les bibliothŤques, puis finit par s'ťtendre ŗ l'ťchelle internationale sous le nom d'Internet.
Les ťchanges au sein d'Internet fonctionnent selon le systŤme de la commutation par paquets : un message ťmis par un ordinateur est dťcoupť en paquets portant l'adresse de l'expťditeur et celle du destinataire, ainsi que les informations nťcessaire pour la mise en ordre des paquets ŗ l'arrivťe. Chaque paquet chemine indťpendamment en employant des voies disponibles entre des ordinateurs relais appelťs routeurs. A l'arrivťe, le message est reconstituť par la remise en ordre des paquets.
Un tel systŤme ne fonctionne que si les ordinateurs connectťs au rťseau disposent chacun d'une adresse les dťsignant de faÁon non ambiguŽ : c'est l'adresse IP (Internet protocol), composťe d'une suite de nombres sťparťs par des points. La version actuellement la plus utilisťe est la quatriŤme, dite Ipv4, qui comprend quatre nombres compris entre 0 et 255. Comme elle arrive ŗ saturation, comme un systŤme d'immatriculation d'automobiles ou de numťrotation tťlťphonique, elle est en train d'Ítre supplantťe par la version 6 dite Ipv6 longue de 16 octets au lieu de 4 et qui permet de formuler... 667 millions de milliards d'adresses par millimŤtre carrť de surface terrestre !
Le dialogue de machine ŗ machine est dťfini par un ensemble de rŤgles appelť protocole. En rťalitť, il n'y a pas un protocole mais tout une pile qu'on peut ainsi schťmatiser :
| 5 | Application | FTP, Telnet, courrier (SMTP, POP), HTTP, streaming (RTSP...), pear to pear (BigTorrent, GNUtella...) |
| 4 | Transport | TCP |
| 3 | Rťseau | IP |
| 2 | Liaison | Ethernet, Token Ring... |
| 1 | Physique | RTC, ADSL... |
Sur Internet :
- Les couches 1 et 2 reprťsentent la liaison matťrielle, par exemple le RTC (rťseau tťlťphonique commutť) ou l'ADSL (Asynchronous Digital Subscriber Line) et le type de rťseau (comme Ethernet ou Token Ring)..
- La couche 3 est occupťe par IP (Internet Protocol), qui gŤre la recherche du meilleur chemin pour envoyer les donnťes ŗ destination.
- La couche 4 est occupťe par TCP (Transmission Control Protocol) qui gŤre la connexion entre les ordinateurs. On dťsigne gťnťralement ensemble ces deux protocoles sous la dťnomination CP/IP, qui constitue le protocole de base d'Internet.
- La couche 5 dťpend du type d'usage d'Internet. Jusqu'ŗ la fin des annťes 1980, il s'est agi essentiellement de :
- FTP (File Transfer Protocol) pour l'envoi d'un fichier vers un autre ordinateur,
- Telnet (TErminal NETwork) pour agir ŗ distance sur un autre ordinateur,
- SMTP (Simple Mail Transfer Protocole) pour envoyer un message et POP (Post Office Protocole) pour rapatrier des messages sur un ordinateur distant.
Jusqu'au dťbut des annťes 1990, travailler sur Internet nťcessitait de manipuler un certain nombre de codes qu'on inscrivait sur des ťcrans en deux couleurs (par exemple noir et blanc). Ceux qui ont connu le Minitel auront une idťe de l'esthťtique de ce premier Internet, mais non de son langage, compris des seuls initiťs.
L'informatique avait fait entre temps connu une double mue gr‚ce ŗ deux innovations essentielles :
- Les interfaces graphiques renvoyŤrent ŗ la Prťhistoire de l'informatique les interfaces en mode caractŤre jusque lŗ prťdominantes et qui reposaient sur une ligne de commande oý l'homme devait taper en langage codť. Dťsormais l'ťcran affichait des pixels, c'est-ŗ-dire de l'image, et l'utilisateur agissait par un dispositif de pointage (la souris, le tapis, la boule...) dans un environnement reposant sur la notion de fenÍtre. C'est la firme Apple qui avec MacIntosh imposa l'interface graphique avant que Microsoft ne rejoigne progressivement ce mouvement avec les versions successives de Windows
li> L'architecture client-serveur repose sur le dialogue entre ordinateurs : les clients, qui envoient des requÍtes, les reÁoivent et les traitent, et les serveurs, qui attendent les requÍtes et y rťpondent. Mais cette description physique il faut ajouter une description logique : on distingue des logiciels clients et des logiciels serveur. Le dialogue entre clients et serveurs ne peut exister que si le client et le serveur utilisent le mÍme ensemble de protocoles.
C'est en 1989 et 1990 que se produisit ŗ GenŤve, au Cern (Centre europťen de recherche nucťlaire), un ťvťnement qui allait bouleverser le monde : l'invention du World Wide Web (aujourd'hui dťsignť sous la forme abrťgťe de " web ") par l'Anglais Tim Berners Lee et le FranÁais Robert Cailliau. On devrait leur ťlever des statues, au moins virtuelles !
Leur idťe fut simple : crťer des pages lisibles sur un ťcran graphique et reliables entre elles par des liens hypertextes. On naviguerait ainsi d'une page ŗ l'autre, celles-ci pouvant se trouver ŗ de grandes distances. D'abord conÁu par Tim Berners-Lee pour le rťseau interne du Cern, ce systŤme fut appliquť ŗ cet Internet dťjŗ vieux de 20 ans mais qui allait alors connaÓtre une destinťe aussi imprťvisible qu'extraordinaire.
Quatre prť-requis ťtaient nťcessaires pour mettre en úuvre cette gťniale invention : l'architecture client-serveur, un protocole, un systŤme d'adresses et un langage.
- L'architecture client-serveur permet de distinguer :
- les navigateurs, logiciels clients dont le mťtier est d'envoyer une requÍte afin de rapatrier une page ou de faire une recherche sur une base de donnťes. Le premier navigateur s'appelait tout simplement WorldWideWeb. Mosaic puis Nestcape, navigateurs en mode graphique, se rťpandirent avant qu'on assiste une suprťmatie d'Internet explorer, de la firme Microsoft, bientŰt battue en brŤche par le logiciel libre Firefox.
- Les logiciels serveur du web sont tout simplement appelťs... serveurs web. Le plus rťpandu dans le monde est le logiciel libre Apache. Leur mťtier est de recevoir les requÍtes des navigateurs et d'y rťpondre en puissant dans des donnťes avec lesquelles ils sont interfacťs.
- Le protocole, c'est HTTP (HyperText Transfer Protocole). Il est extrÍmement simple car il prťvoit pour l'essentiel une ou plusieurs requÍtes du client et la ou les rťponses du serveur. Il prťvoit huit types de requÍtes, appelťes mťthodes, dont les principales sont GET (demander une ressource ŗ un serveur web) et POST (envoyer des informations ŗ un serveur web). Nous y reviendrons.
- Le systŤme d'adresses, c'est :
- une syntaxe rťgissant le libellť des URL (United Resource Locator) : protocole, nom de domaine, ťventuellement chemin d'accŤs dans l'arborescence des rťpertoires et nom de fichier ou libellť d'une requÍte ;
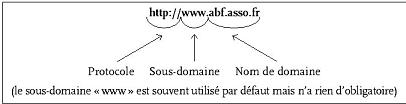
URL d'une page d'accueil
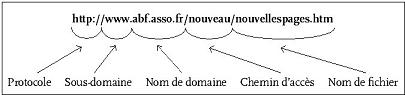
URL d'une page dťsignťe par son nom de fichier (ancien site de l'ABF) - une gestion des correspondances entre l'adresse " en clair " (de type www.abf.asso.fr) et l'adresse IP, gr‚ce aux serveurs DNS (Domain Name Serveur).
- une syntaxe rťgissant le libellť des URL (United Resource Locator) : protocole, nom de domaine, ťventuellement chemin d'accŤs dans l'arborescence des rťpertoires et nom de fichier ou libellť d'une requÍte ;
- Le langage, c'est HTML (Hyper Text Mark-up Langage). Il ne vient pas du nťant. Il s'agit d'une simplification de SGML (Standard Generalized Mark-up Langage), utilisť dans certains secteurs industriels ŗ partir des annťes 1980 et reposant sur le principe des balises (en anglais mark-up). Une balise entrante et une balise fermante encadrent du texte ou une image.
Exemple : <p>Ceci est un paragraphe</p>
HTML permet de donner forme au texte et aux ťlťments graphiques figurant sur une page, mais son intťrÍt essentiel est de gťrer des liens qui sont de deux sortes :- Les liens hypertextes cliquables sur un ťlťment appelť ancre.
Exemple : <a href="http://www.abf.asso.fr">ABF</a>, " href " signifiant hypertext reference. Ce codage rend l'expression " ABF " cliquable et permet de se connecter au site del'ABF. - Les liens non cliquables permettant l'apparition directe sur la page d'un ťlťment prťsent sur un autre site.
Exemple : <img src="http://www.abf.asso.fr/logo-abf.jpg"> pour faire apparaÓtre le logo de l'ABF.
- Les liens hypertextes cliquables sur un ťlťment appelť ancre.
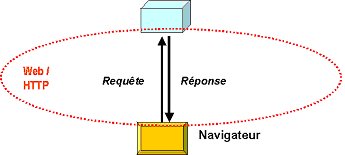
Le dialogue entre le navigateur et le serveur web
C'est l'invention du web qui a en quelques annťes rťpandu l'usage d'Internet dans le monde entier et auprŤs de toutes les catťgories d'usagers : le monde scientifique et de l'ťducation, les entreprises, les administrations, le grand public. C'est elle qui a permis que les services non web d'Internet se rťpandent parallŤlement, ŗ commencer par la messagerie. En mÍme temps, le web est devenu une plate-forme pour ces services.
Le web est ŗ l'origine, et est encore en grande partie, fait de pages statiques qu'on ne peut mettre ŗ jour qu'en les remplaÁant. On peut bien sŻr les ťcrire en HTML " dans le texte ", mais une premiŤre gťnťration de logiciels de crťation de sites web est apparue : les ťditeurs HTML, qui permettaient d'ťcrire des pages presque aussi facilement qu'on ťcrit un courrier avec un traitement de texte. On les chargeait ensuite sur son site gr‚ce au protocole FTP.
Mais le web a aussi bientŰt servi ŗ interroger des bases de donnťes, par exemple des catalogues de bibliothŤques. Au dťbut des annťes 1990, on ne pouvait le faire que par le protocole Telnet qui permettait de simuler un terminal en mode graphique.
Puis on a inventť l'interfaÁage web des bases de donnťes :
- le navigateur envoie une requÍte ;
- l'interface web la reÁoit, la traduit dans un langage comprťhensible par la base de donnťes et la lui envoie ;
- cet interface reÁoit la rťponse de la base de donnťes et l'enveloppe dans une page web gťnťrťe ŗ la volťe, que le serveur web envoie au navigateur ;
- l'usager prend connaissance de la rťponse gr‚ce ŗ une page web qui a ťtť gťnťrťe pour lui.
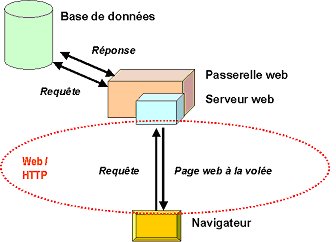
Schťma d'interrogation d'une base de donnťes par le web
Ce principe a permis de dťvelopper toutes sortes de services sur Internet : acheter des marchandises en ligne, recherche un horaire de chemin de fer, utiliser une plate-forme de e-administration, interroger un catalogue de bibliothŤque et bien sŻr un moteur de recherche.
On a vu que le protocole http permettait, gr‚ce ŗ sa mťthode POST, d'envoyer des donnťes vers un serveur. Les pages ou portions de pages comportant des champs de saisie sont appelťs des formulaires, usage prťvu par le langage HTML. Il arrive souvent que la requÍte gťnŤre un URL qui peut Ítre sauvegardťe dans ses favoris. On le reconnaÓt en ce qu'il comporte souvent un point d'interrogation :
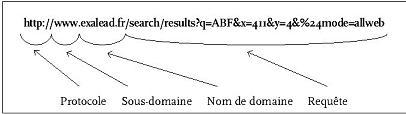
URL d'une requÍte dans le moteur de recherche Exalead
La messagerie fait partie des applications gťrables ŗ partir de formulaire. Quand on utilise un logiciel spťcialisť de messagerie tel qu'Outlook ou Lotus Notes, on se sert d'un client qui ťmet selon le protocole SMTP et reÁoit selon le protocole POP des donnťes qui arrive sur so disque dur. Mais quand on fait de la messagerie sur le web, on utilise tout simplement la mťthode POST du protocole HTTP.
Mais revenons aux sites web proprement dit. Le systŤme des pages statiques posait un problŤme : si on voulait conserver un environnement constant pour des raisons d'image et de navigation ou le faire ťvoluer en fonction des besoins, il fallait corriger une ŗ une chacune des pages ! Pour rťsoudre ce problŤme, on a d'abord eu recours au systŤme des frames (cadres) qui permettait de gťrer diffťrentes portions d'un ťcran dans des fichiers diffťrents. On pouvait ainsi gťrer chacune d'elle sťparťment.
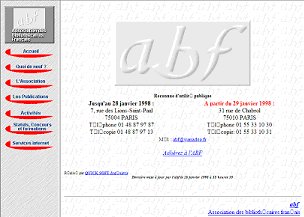
Le premier site de l'ABF comportait deux frames, celui de gauche comportant le menu.
Mais ce systŤme avait le grand dťsavantage de perturber le principe de l'hypertexte. Un lien vers un fichier ne permettait souvent d'afficher qu'une portion du site dont on perdait l'environnement global. Et quand on repťrait une page intťressante sur le site, on ne pouvait pas, sans une manipulation connue des plus expert, la sauvegarder dans ses favoris ; on ne sauvegardait d'une page d'accueil.
Un nouveau mode de gestion de site est alors apparu : les CMS (Content Management Systems), qui battirent en brŤche les ťditeurs HTML. Le protocole FTP ne sert plus qu'ŗ charger des images fixes ou animťes ou des documents joints. Tout se passe en ligne, sur le web, gr‚ce au systŤme des formulaires et donc ŗ la mťthode POST du protocole HTTP. L'administrateur construit un squelette, et les gestionnaires du sites n'ont plus qu'ŗ crťer des rubriques, sous rubriques et article gťnťrant autant de pages.
Les sites ainsi gťrťs sont dits dynamiques. Quand on clique sur un ťlťment d'un menu ou un mot clť, on gťnŤre une requÍte qui provoque l'envoi d'une page web crťťe ŗ la volťe. Une base de donnťes, souvent gťrťes avec le SGBD (systŤme de gestion de base de donnťes) MySQL, contient les informations qui permettront de gťnťrer les pages.
Une partie de ses sites sont gťrťs gr‚ce au langage PHP (Personnal Home Page). Quant aux logiciels de CMS, il en existe bien sŻr un grand nombre, mais l'un des plus rťpandu en France est un logiciel libre : SPIP (SystŤme de publication pour l'internet partagť).
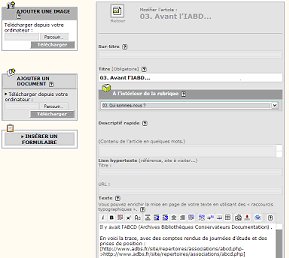
Ecran de gestion sous Spip du site de l'Interassociation archives-bibliothŤques-documentation
On reconnaÓt les URL d'un site gťrť avec un CMS ; hormis les pages d'accueil, car ils se terminent non par un nom de fichier mais par une requÍte, comportant souvent un point d'interrogation :
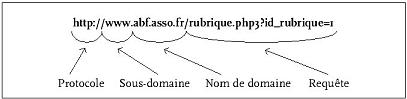
URL d'une page du site ABF
Une bonne partie des sites gťrťs avec un CMS offrent deux possibilitťs :
- ils permettent d'accorder aux internautes le droit de poster des commentaires, toujours gr‚ce aux formulaires et donc ŗ la mťthode POST du protocole HTTP ;
- ils ťmettent des flux RSS.
Les logiciels permettant de crťer des blogs ou des wikis sont des CMS. Toujours avec la mťthode POST d'HTTP !
Voilŗ oý nous en sommes de cette histoire. Mais il fait signaler qu'entre temps se sont dťveloppť :
- le langage XML (eXtended Mark-up Language), plus simple que SGML mais plus complexe qu'HTML, et qui permet de dťcrire des donnťes mais aussi des messages vťhiculťs par les protocoles ;
- toutes sortes de formats de son et d'images, fixťes ou animťes, sonorisťes ou non ;
- des protocoles de diffusion en continu (en anglais streaming comme RTSP (Real Time Streaming Protocol) qui permettent de lire un flux audio ou vidťo et reposent sur TCP/IP mais n'ont rien ŗ voir avec http ;
- des protocoles pour la communication directe entre ordinateur, appelťe pair ŗ pair (en anglais Peer to Peer) comme BigTorrent ou GNUtella.
C'est cette sťrie de protocoles et de formats qui a rendu possible le Web 2.0. Vraiment, quelle histoire !
[Le passage suivant n'a pas ťtť publiť]
En voici, par ordre d'apparition dans ce rťcit, les ingrťdients. Les reconnaÓtrez-vous ?
|
Web Internet commutation par paquets routeur adresse IP Ipv4 Ipv6 protocole RT ADSL IP TC TCP/IP FTP Telnet SMTP |
POP interfaces graphiques mode caractŤre client-serveur clients serveurs World Wide Web liens hypertextes navigateurs serveurs web HTTP GET POST URL DNS HTML SGML |
pages statiques ťditeurs HTML ŗ la volťe formulaires CMS sites dynamiques PHP SPIP blogs wikis XML streaming RTSP Peer to Peer BigTorrent GNUtella. |